はじめに
初めまして。onimayuです。
皆さん「サーバーレス」という言葉は聞いたことがあるでしょうか?
筆者はこれまでサーバレスでのWebアプリケーション開発を主に経験してきたので、今回はサーバーレス開発の以下について記事を書かせていただきます。
サーバーレスについて知らない方は「サーバーレスとは何か」について簡単にまとめたのでそちらから。
知っている方は「サーバーレス開発で学んだアーキテクチャ思考」に上の目次からジャンプしていただけたらと思います。
サーバーレスとは何か?(知らない人向け)
言葉どおりだとサーバーがないの?と思ったりしますが、サーバーが存在しないわけではありません。アプリケーションを構築するためのサーバーは、クラウド(AWSやGCPなど)のものを借りることを前提としています。
そのため、「サーバーレス=サーバー管理が不要」という意味です。
「IaaS / PaaS / SaaS / FaaS」という風にクラウドの利用形態は分けられますが、自分は主に「FaaS(Function as a Service)」で利用して開発を行っていました。これは、開発に必要なサーバーやデータベースなどのインフラをクラウドサービスに一任して、プログラミングで作成した処理の定義や実行のみを行います。
具体的なサービスとしては、AWSであれば「AWS Lambda(ラムダ)」、GCPであれば「Google Cloud Functions」、Azureであれば「Azure Functions」があります。
処理は、イベントをトリガーとして動くイメージです。

メリットは公式のAWSの説明ページがわかりやすいです。
処理を実行した分だけ課金される従量課金制なので、大量のアクセスや高負荷が長く続く処理を必要とする場合には向いていないと思いますが、個人的には低予算でちょっとした機能を早く実現したい!といったニーズにはとてもマッチしやすいと思います。
サーバーレス開発で学んだアーキテクト思考
自身が携わってきたプロジェクトや他チームのプロジェクトを見ていて上手くいっているところもあれば、開発と運用共に大変そうなプロジェクトも見てきました。
特にその大変そうなプロジェクトで採用してしまった(というより成り行きでそうなってしまったのか)アーキテクチャのアンチパターンと、それを避けるための先輩方に教わった設計思考を紹介したいと思います。
自身の経験上、サーバーレス開発での事例を前提に書いていますが、それ以外の開発でもこの考え方は活かせると感じています。
アンチパターン例
プログラムの再利用性や拡張性を考慮せずに開発を急いでしまったがために、バグが大量に発生し、修正するにも修正箇所の特定が困難なスパゲッティーコードができあがり・・・
いざ運用開始をするも、あとの運用保守が大変な状況となってしまっているプロジェクトを見てきました。
なぜそうなってしまっていたのかの大きな原因の一つは、垂直分散構造でソースコードを組み立ててしまっていたことでした。
以下の図をご覧ください。
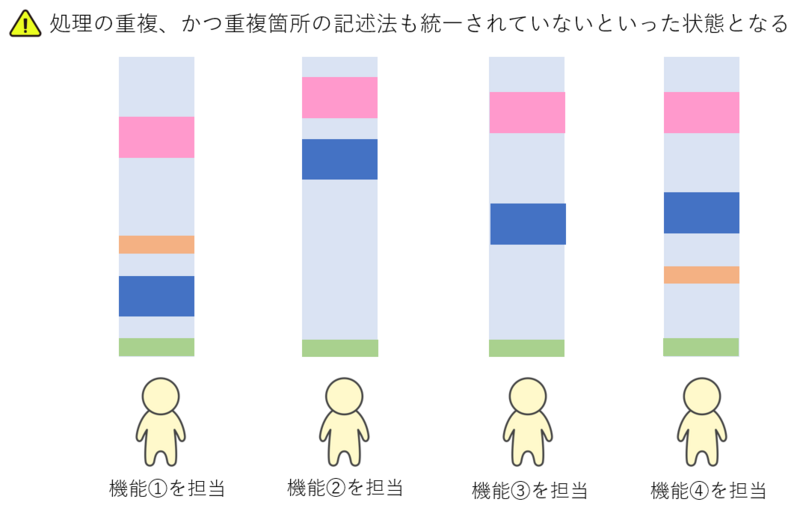
なんだかカラフルですね。
同じ色=同じ処理を記述していることを表しています。
イメージしやすいのは、例えば機能①が「データAの登録機能」で、機能②が「データAを加工して更新する機能」だとします。
どちらも、同じデータを扱い、同じデータベースに対して登録、更新などの処理を行う必要があります。データベースへまずは接続する必要がありますから、「データベースへの接続処理」は共通した処理になるのですが、このチームは上手く連携ができておらず、機能①を担当した人と、機能②を担当した人が個々に「データベースへの接続処理」を書いてしまっているといったイメージです。
アンチパターンで突き進んだ結果
そして各々で機能が完成し、個々の機能は上手く動作することを確認できました。さー、全てを連携させて動かしてみよう!とすると、大抵はどこかしらでバグが起こります。
開発中にバグが全く発生しないようなことはほぼないと思います。そしてそのバグの箇所を特定して修正します。
🧑🏻💻「このエラーはこの機能のここで起こっているな。よし、直した。あれ、また別のここでも同じエラーが出ているな・・・。よし!直した!てあれ、ここでも起きてるな。あれ、ここでも!」
🤯🤯🤯🤯🤯🤯🤯🤯
ある箇所を修正したら、どこに影響範囲があるのかをソースコードの隅々まで目を通さないといけません。
作業の分担が容易で完成までのスピードは比較的早いと思いますが、個人的には相当チームで連携が上手くできていないと、完成までは早いというメリットがあったとしても、重複コードが散乱して、とても脆く、運用保守のコストが高くついてしまうリスクがあります。
水平分散型アーキテクチャの導入
上記アンチパターンは、垂直分散構造であるとしていましたが、それと対をなすものが水平分散構造です。
図を簡単に作ってみました。下に行くにつれて、OSやデータベースと近くなります。

先ほどの垂直分散型と違うのは、3つの層に分かれていて、行う処理の責務が単一のコンポーネントとして独立しています。
メリット
この構成では、同じ処理が色々なところに点在してしまうリスクを避けることができます。
プレゼンテーション層は、例えばAWSでいうLambdaのハンドラーとなるファイルにあたり、動作に必要な業務ロジックにかかる処理はドメイン層にあるモジュールを使い、一番下のデータ層の処理に直接かかわることはありません。
そのため、図中にも書いたように、プレゼンテーション層を実装する開発者は業務ロジックや外部APIの具体的な中身の処理・使い方を知らなくても、ドメイン層のとあるメソッドを使いたいとしたら、必要なパラメータを渡して呼び出すだけでいいのでとてもシンプルになり、共通化も図れ、スッキリします。
どこかでバグが発生した場合でも、それがドメイン層の一か所で発生していたとしたら、そこを直しさえすれば、ソースコードを全て追わずとも、そのモジュール使用箇所すべてに修正が適用され、隅々までコードを追って影響範囲を確認しなくてもよくなります。
ディレクトリ構成例(Lambda)
具体的なディレクトリ構成に落とすと以下のようなざっくりイメージです。
※サーバーレス開発でディレクトリ構成を考える場合、自由度が高いと思うのであくまでも簡単な一例としてご覧ください。
root/
├ handlers/
│ ├ create_tag.js
│ ├ delete_file.js
│ └ upload_file.js
├ layers/
│ ├ commons/
│ │ ├ database/
│ │ │ └ connection.js
│ │ ├ s3/
│ │ │ └ s3.js
│ │ ├ dynamo/
│ │ │ └ dynamo.js
│ │ └ slack/
│ │ └ slack.js
│ ├ domains/
│ │ ├ types/
│ │ │ └ types.js
│ │ ├ auth.js
│ │ ├ notifier.js
│ │ └ file_manager.js
└ etc...
handlers/: Lambdaハンドラーになるファイルを格納layers/: Lambdaハンドラーから呼び出されるファイルを格納commons/: データ層にあたるDBやAWSリソース、外部APIにアクセスするメソッドを定義したファイルを格納domains/: ドメイン層にあたる業務ロジックを構成するメソッドを定義したファイルを格納types/: 共通のデータ種別などを定義したファイル
デメリット
データ層やドメイン層を作るためには抽象化の粒度や定義が重要で、ここの層で上手く動かないとなると呼び出す箇所全てに影響が出てしまいます。そのため、仕様に理解があるのと同時に、オブジェクト指向開発の経験が比較的ある方でないと設計の難易度が高いと思います。
(自分なんかはまだまだです)
あとは、データ層とドメイン層の完成まで比較的時間がかかり、ドメイン層までできてやっとプレゼンテーション層の作成に着手できることから、一つの機能の完成を見るまでに時間がかかり、はたから見たら、開発が進んでいないんじゃないかともどかしく思われるかもしれません。
※ドメイン層まで一旦できてしまえば、プレゼンテーション層であるハンドラーの実装は比較的楽にかつ早くできます。
完成までの開発スピード(体感値)
しっかり水平分散型のアーキテクチャで開発を進められた場合には、後半にいくにつれてぐいっとスピードが上がります。
垂直分散構造で開発を進めてしまい、うまくいっていない場合はオレンジ線のような体感値だと思います。
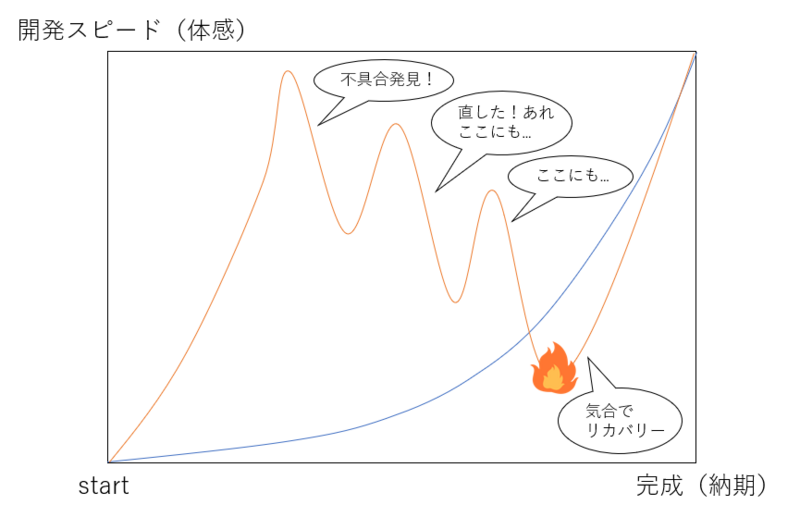
(炎で燃えているのはお察しください・・・)
アンチパターンを見てきたからこそ、水平分散型アーキテクチャの有用性を開発を通して実感することができました。
さいごに
ここまで読んでいただいてありがとうございました!
先人の先輩方より、拡張性・変更容易性を確保していかにアプリケーションの寿命を延ばすのかという、開発する人だけではなく、アプリケーションを使う人のことを考えても、とても重要な思考を学ぶことができたと思っています。
今はReactとTypeScriptを使ったフロントエンドの開発に勤しんでいる筆者ですが、フロントエンドでも今回紹介した考え方はけっこう活きているなと感じています。
この記事が誰かの参考になりますと幸いです😊