
はじめに
こんにちは、山本です。OpenAIのDALL·E 2やStable Diffusionのような画像生成AIが2022年にリリースされ話題になりました。このような技術を用いたアプリの「AIピカソ」で「いらすとや」風のイラストを生成できるというニュースがありました。
筆者もこんな風に「いらすとや」の画像を自動生成したいと思いStable Diffusionについて調べました。この記事では簡単な画像生成AIの説明と「いらすとや」の画像をLoRAを用いて学習させるコードを共有します。
Stable Diffusionとは?
まず、簡単にStable Diffusionについて説明します。ユーザが入力した文章から画像を自動生成するAIです。仕組みを簡潔にいうと、画像から作成したノイズと文章からAIが学習し、ランダムに作成したノイズと文章から画像を生成します。
LoRAとは?
LoRA(Low-Rank Adaptation)は学習済みモデルを新しいデータで学習させる方法の一つです。特徴として、学習時に必要な計算量が少なくなるため、学習に必要な時間やメモリの使用量を抑えることができます。これを使うことで、Stable Diffusionのモデルを少ない学習画像で短時間で学習をすることができます。
実際にやってみる
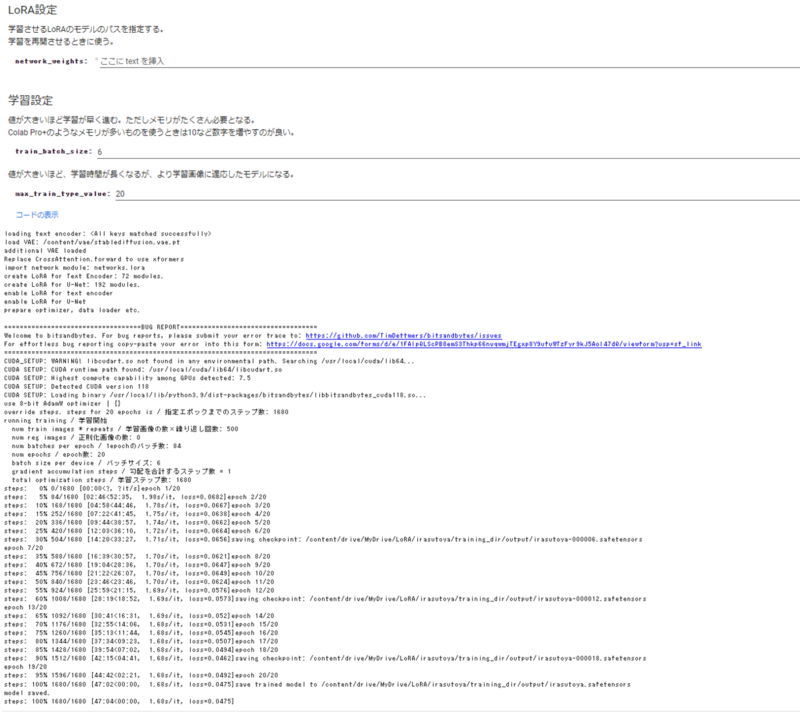
LoRAでモデルを作成するコードを作成しました。Colaboratoryで動くため、GPUがなくても大丈夫です。コードにある説明の通りに進めていけば「いらすとや」風の画像を生成するモデルが作成できます。
このコードはfast-kohya-trainer.ipynbを参考にして作成しました。
こちらが学習時のログです。
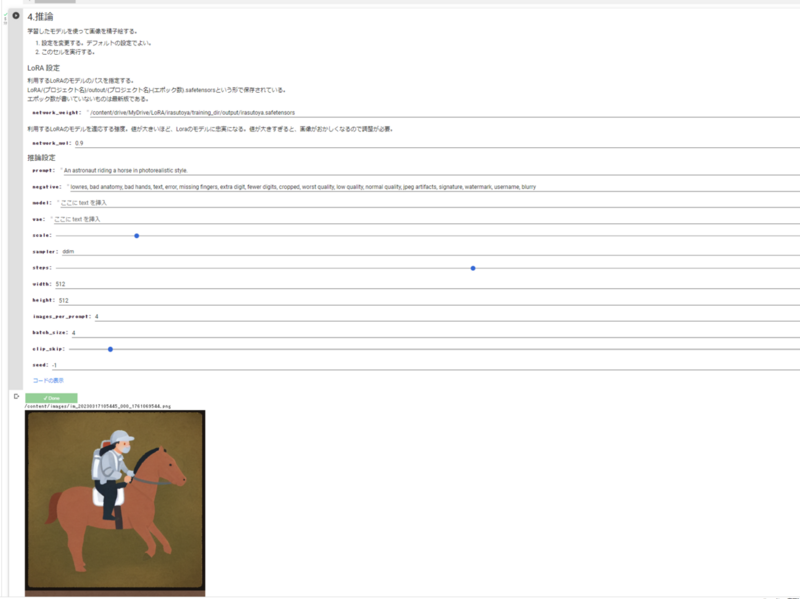
こちらは「いらすとや」を学習したLoRAのモデルでの画像生成の結果です。
作成したモデルをstable-diffusion-webuiで使う
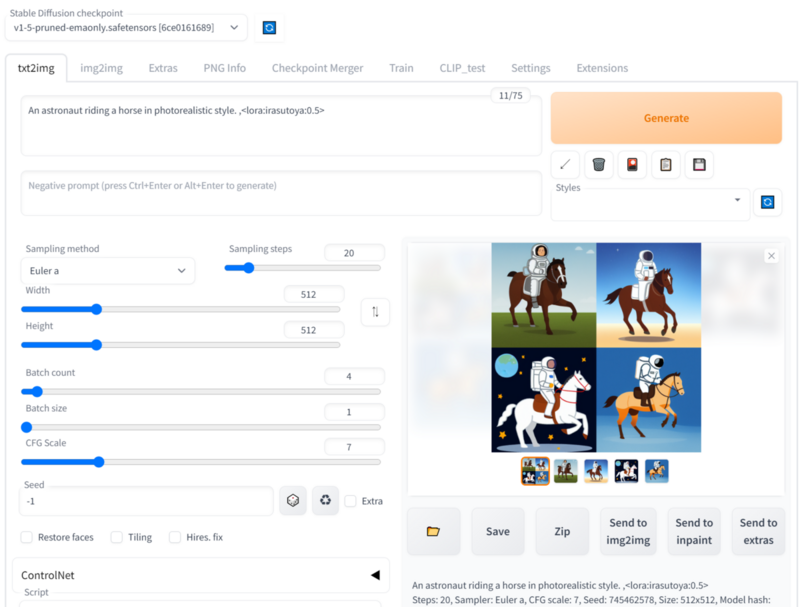
続いて、作成したLoRAのモデルをstable-diffusion-webuiで利用する方法を紹介します。stable-diffusion-webuiの起動方法はここでは説明しません。
作成したLoRAのモデルをmodels/Stable-diffusion/Lora/irastoya.safetensorsに保存し、WebUIのプロンプトに<lora:irasutoya:1>タグを挿入することで適用できます。数字は適用される強度を表します。例えば、<lora:irasutoya:0.5>とすると「いらすとや」に似すぎない絵を生成できます。
おわりに
本記事では「いらすとや」風の画像を出力するモデルの作成方法を紹介しました。LoRAモデルをつくると目的に合わせた絵を簡単に生成できるようになり、Stable Diffusionでの創作活動の幅が広がることが期待できます。
ただし、画像生成AIによって生成された画像の多くは体の構造が正確ではないため、利用することができないものがあります。そのため、画像生成AIを利用する際には、プロンプトやパラメータを何度も変更し、試行錯誤をする必要があります。これはいわゆるガチャというやつです。画像を生成すること自体は簡単ですが、満足できる結果を得るためには時間がかかります。